| Match strength | Parent-only Jaccard | Full-document Jaccard |
|---|---|---|
| weak | 10 | 21 |
| none | 113 | 102 |
Where do Cyber.org K-12 and CSTA standards lexically align?
Pairwise text similarity with and without prose-encoded examples
Cross-framework
K-12
Pedagogy
Pairwise Jaccard similarity between 123 Cyber.org K-12 parent standards and 140 CSTA K-12 CS parent standards, with and without each side’s clarification-derived examples. The contrast between parent-only and full-document similarity is the methodological finding.
The question
For each Cyber.org K-12 standard, what is the closest CSTA K-12 CS standard by text similarity, and how does that closeness change when each side’s prose-encoded examples (Cyber.org clarification statements, CSTA clarification-column content) are included alongside the parent statement text?
Why it matters
Cyber.org and CSTA are the two most widely-referenced K-12 standards sets covering cybersecurity content in US classrooms. Practitioners frequently ask whether a curriculum aligned to one is implicitly aligned to the other. The naive comparison (parent text against parent text) understates the alignment because the two frameworks encode pedagogical detail differently. Cyber.org embeds clarifications directly inside the numbered standard’s prose. CSTA stores them in a separate clarification column.
cybedtools v0.2.0 reclassifies both forms of clarification content as cybed:Example nodes, distinct from parent statements and from parser-extracted cybed:Subpoint bullets. That vocabulary distinction is what makes a fair cross-framework comparison possible. The full-document text for a parent is the parent statement plus all of its cybed:hasExample and cybed:hasElement children, concatenated and tokenized as a single document.
The parent-only-vs-full-document contrast is the finding.
The result
The full-document pass roughly doubles the count of detectable matches (10 to 21) over the parent-only pass. None reach the moderate tier (Jaccard ≥ 0.20) under either pass.
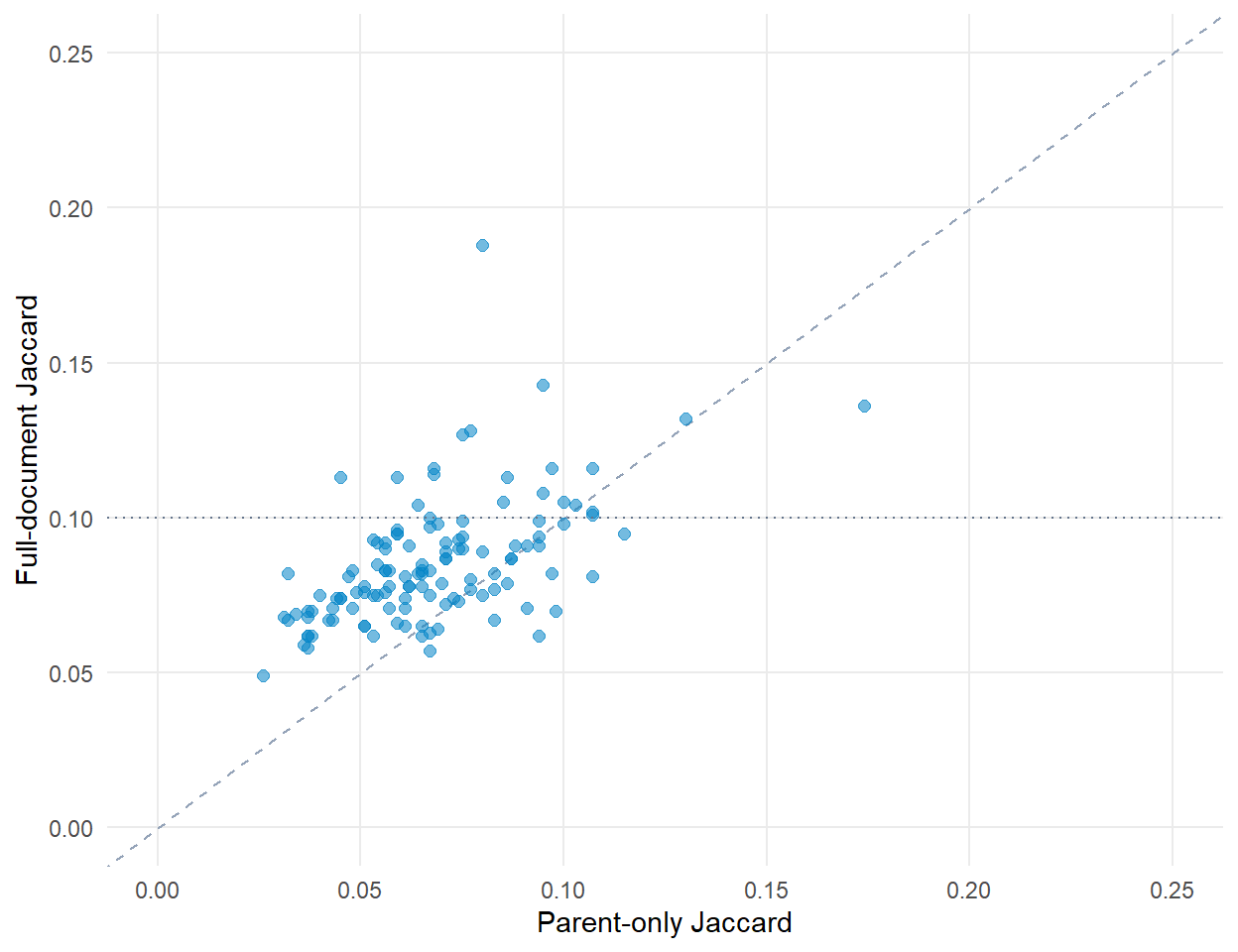
The points cluster above the 1:1 line. Full-document scoring systematically raises best-match similarity over parent-only scoring. The dotted horizontal line marks the 0.10 threshold below which no match is reported.
What this tells us
The vocabulary distinction matters
Compare Cyber.org and CSTA at the parent-statement level only and you find 10 of 123 Cyber.org standards with a CSTA match. Compare full documents (parent plus Subpoints plus Examples) and you find 21. Eleven Cyber.org standards have a plausible CSTA counterpart that is invisible to the parent-only comparison.
The frameworks are still largely complementary
Even on the full-document pass, 102 of 123 Cyber.org standards (83%) have no detectable CSTA match. Cyber.org covers cybersecurity-specific territory (threat actors, social engineering, physical security, risk-management foundations) that the CSTA K-12 CS Standards do not address.
What this doesn’t tell us
Lexical similarity is not coverage
A Jaccard score of 0.10 to 0.20 means 10-20% of the unique vocabulary is shared. Suggestive, not dispositive. A teacher claiming CSTA coverage from a Cyber.org-aligned lesson should read both standards and decide whether the same cognitive demand is met. The tool surfaces candidates. The practitioner makes the equivalence judgment.
Grade-band drift is not corrected for
The strongest match in this data pairs a Cyber.org 6-8 standard with a CSTA 3A (grades 9-10) standard. Topic alignment is real. Cognitive-level alignment is not. This is a known limitation of any vocabulary-similarity approach to cross-framework comparison and applies equally to other K-12 cyber crosswalks (NICE, NCyTE materials).
The metric is one of several reasonable choices
Jaccard on unigrams is interpretable and fast, but ignores word order, multi-word phrases, and synonymy. Other choices (cosine on TF-IDF vectors, embedding-based similarity, manually-curated crosswalk) trade interpretability for sensitivity. The cybedtools v0.2.0 SPARQL helpers return the structured graph, and downstream analysts can run whichever similarity metric suits their question.
Look up your standard
The widget below shows every Cyber.org K-12 standard alongside its closest CSTA match (full-document Jaccard). Search by topic word (“network,” “encryption,” “PII”) to find your standards quickly, or sort by overlap to see the strongest candidates first.
The full row count is 123, one per Cyber.org standard. Standards with no detectable CSTA match (overlap below 10% under the methodology above) appear with their closest candidate even though that candidate is not a defensible coverage claim. The “no detectable match” bracket on the persona page is the same data filtered to overlap below 10%.
Reproduce this
library(cybedtools)
library(dplyr)
library(stringr)
library(purrr)
library(tidyr)
library(rdflib)
g <- load_combined_ntriples_graph()
# Pull parent standards (excludes Subpoints + Examples).
prefix_block <- paste0(
"PREFIX cybed: <https://w3id.org/cybed/ontology#>\n",
"PREFIX cyberorg: <https://cyber.org/standards/terms#>\n",
"PREFIX csta: <https://csteachers.org/k12standards/terms#>\n"
)
query_subjects <- function(rdf, type_iri) {
q <- paste0(prefix_block, sprintf("SELECT ?s WHERE { ?s a %s }", type_iri))
res <- rdflib::rdf_query(rdf, q)
if (nrow(res) == 0) tibble::tibble(s = character(0)) else tibble::as_tibble(res)
}
cyberorg_parents <- query_subjects(g, "cyberorg:Standard") |>
transmute(element = s, framework = "cyberorg")
csta_parents <- query_subjects(g, "csta:Standard") |>
transmute(element = s, framework = "csta")
# Attach element text.
elem_text <- sparql_pairs(g, "cybed:elementText") |>
transmute(element = s, text = o)
# Attach Subpoint + Example children for full-document comparison.
has_element <- sparql_pairs(g, "cybed:hasElement") |>
transmute(parent = s, child = o)
has_example <- sparql_pairs(g, "cybed:hasExample") |>
transmute(parent = s, child = o)
all_links <- bind_rows(has_element, has_example)
# Build full-document text per parent (parent + all child text concatenated).
# Tokenize, drop stopwords and short tokens, compute Jaccard pairwise,
# keep best CSTA match per Cyber.org standard. The full prep script is
# in `concordance/_data-prep-k12-alignment.R` in the repository.The data file shipped with this page (_data/k12_alignment.rds) is the output of that prep script run against cybedtools v0.2.0. Re-run the prep when the package or the staged framework data changes.
Use case using this data
- Tasha cross-walks her Cyber.org-aligned cyber unit to CSTA, the practitioner-facing version of this analytic question.