| Framework | Type | Jurisdiction | Units | Strict elements | With examples | Per unit (strict) | Per unit (with ex.) |
|---|---|---|---|---|---|---|---|
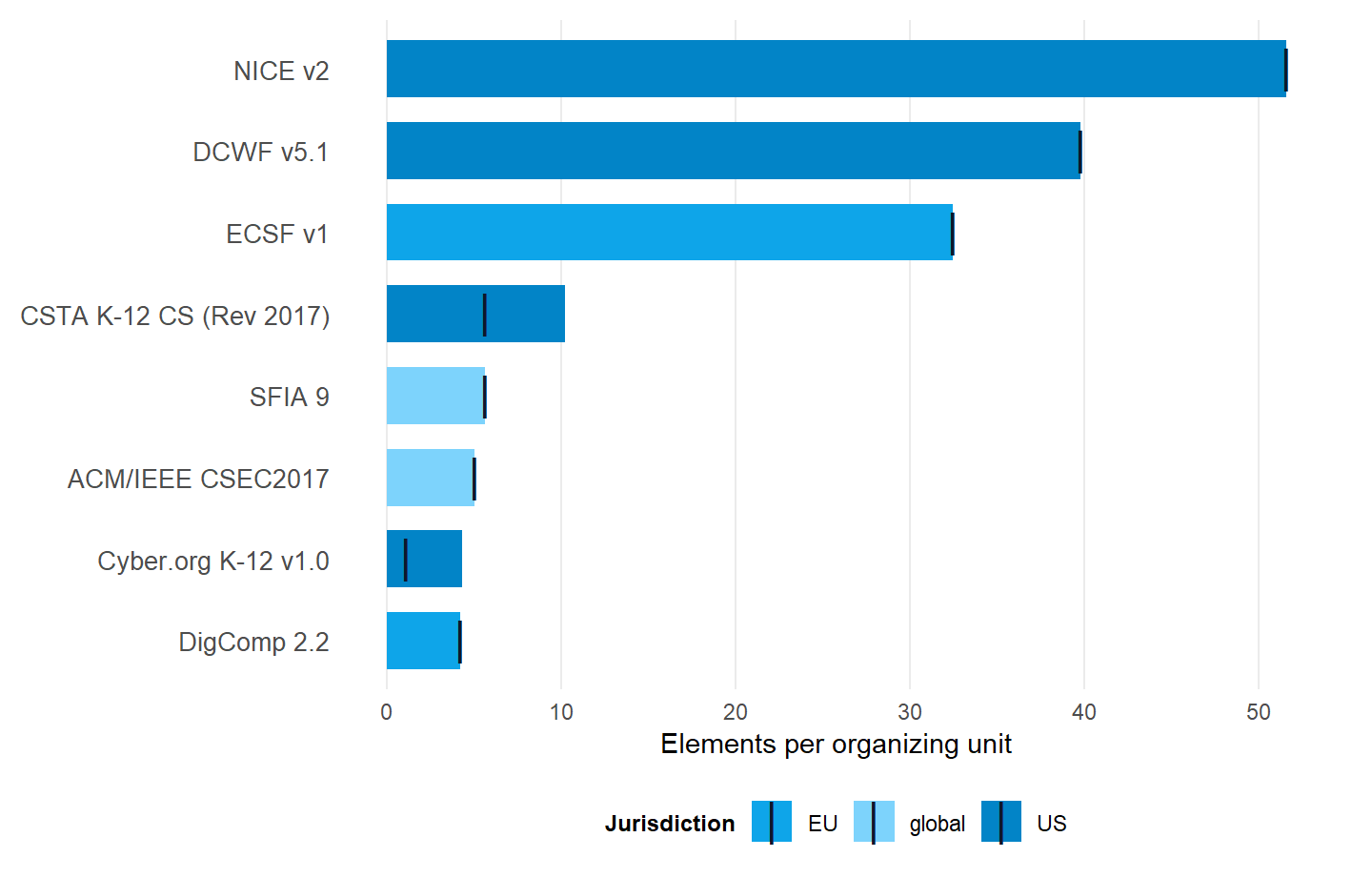
| NICE v2 | Workforce | US | 41 | 2115 | 2115 | 51.6 | 51.6 |
| DCWF v5.1 | Workforce | US | 74 | 2945 | 2945 | 39.8 | 39.8 |
| ECSF v1 | Workforce | EU | 12 | 390 | 390 | 32.5 | 32.5 |
| CSTA K-12 CS (Rev 2017) | Pedagogy | US | 25 | 140 | 254 | 5.6 | 10.2 |
| SFIA 9 | Workforce | global | 147 | 830 | 830 | 5.6 | 5.6 |
| ACM/IEEE CSEC2017 | Pedagogy | global | 8 | 40 | 40 | 5.0 | 5.0 |
| Cyber.org K-12 v1.0 | Pedagogy | US | 116 | 123 | 500 | 1.1 | 4.3 |
| DigComp 2.2 | Pedagogy | EU | 5 | 21 | 21 | 4.2 | 4.2 |
How does element density vary across frameworks?
Per-unit density, strict and with examples
Cross-framework
Per-unit element density across the framework corpus, strict and with examples. The twelvefold-spread finding, reframed as a comparison of design philosophy rather than a quality ranking.
The question
How many elements does each framework specify per top-level organizing unit, and how does that count change when prose-encoded examples are included alongside numbered standards?
Why it matters
Per-unit density is easy to mis-read as a quality ranking. It isn’t one. What the figure measures is how granular each framework’s stewards chose to be when they decided what work, what knowledge, or what competence belongs to a single organizing unit. NICE specifies tasks, knowledge statements, and skill statements per work role at one level of granularity. DigComp specifies competence areas at a different level, designed for citizen self-assessment. Both are valid specifications answering different questions.
The result
What this tells us
Three observations carry weight.
The spread is real and large
The headline figure is roughly twelvefold (NICE 51.6 against DigComp 4.2, examples included). The strict-count spread is forty-sevenfold (NICE 51.6 against Cyber.org K-12 1.1, examples excluded). Either way, the gap merits an explanation.
The spread reflects design philosophy
NICE was built to be operationally specific. It supports workforce planning at the position-description level for the United States federal government, and the granularity is the point. DigComp was built for citizen self-assessment, so the unit of specification is necessarily coarser. SFIA sits in the middle on purpose, the legacy of its history as a global IT-skills catalog. Not as fine-grained as NICE. Not as coarse as DigComp.
The strict-vs-with-examples gap is informative on its own
Frameworks that encode pedagogical detail in prose clarification statements (Cyber.org K-12, CSTA) widen substantially when those examples are folded in. Workforce frameworks (NICE, DCWF, ECSF, SFIA) don’t move, because every bit of detail they ship is already in a numbered statement. Read the gap as a proxy for how much pedagogical scaffolding lives outside the numbered taxonomy.
What this doesn’t tell us
Density is not quality
A framework with high per-unit density isn’t better-specified than one with low per-unit density. The denominator (organizing units) is a design choice, not a corpus property, and different denominators rerank the list.
Strict counts undercount frameworks that encode detail in prose
The 47x strict spread overstates the specificity gap because it ignores the prose-encoded detail in the pedagogy frameworks. Use the with-examples figure when the comparison crosses the workforce-pedagogy boundary.
Reproduce this
The framework_summary tibble ships with the package as a lazy-loaded data object. It is built from the canonical pipeline run documented in data-raw/build-framework-summary.R and tagged at each release.